Tutorial: Scanning Barcodes / QR Codes with OpenCV using ZBar
Categories Computer Vision, Uncategorized
With the ZBar library, scanning Barcodes / QR codes is quite simple. ZBar is able to identify multiple bar code /qr code types and able to give the coords of their locations.





This tutorial was written using:
Microsoft Visual Studio 2008 Express
OpenCV 2.4.2
Windows Vista 32-bit
ZBar 0.1
You will need OpenCV installed before doing this tutorial
Tutorial here: http://ayoungprogrammer.blogspot.ca/2012/10/tutorial-install-opencv-242-for-windows.html
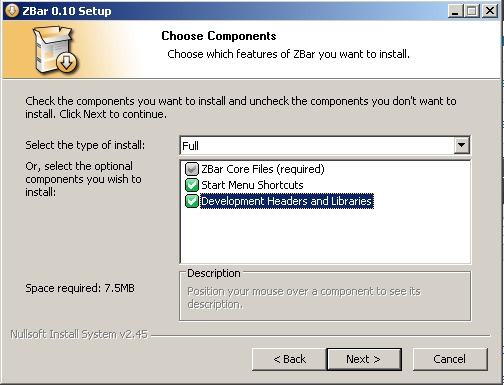
1. Install ZBar (Windows Installer)
http://sourceforge.net/projects/zbar/files/zbar/0.10/zbar-0.10-setup.exe/download
Check install developmental libraries and headers (You will need this)

Install ZBar in the default directory
“C:Program FilesZBar”
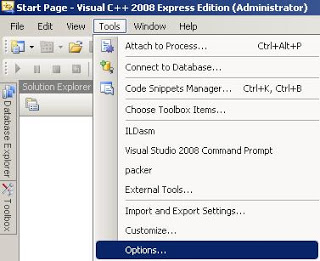
2. Import headers and libraries
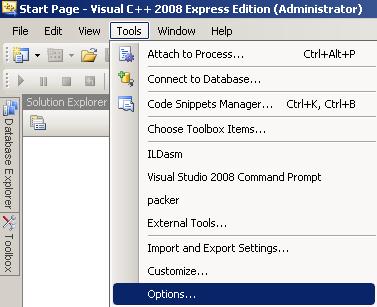
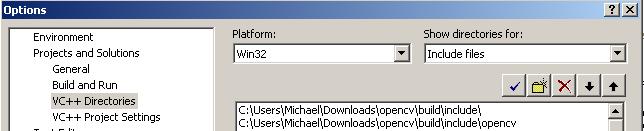
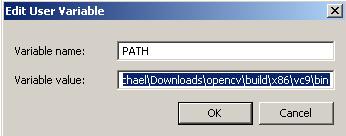
Tools ->Options

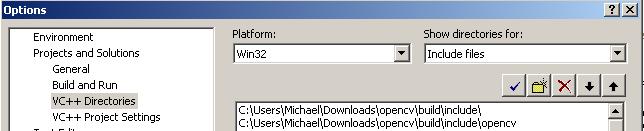
Projects & Solutions -> VC++ Directories

Go to “Include files” and add: “C:Program FilesZBarinclude”
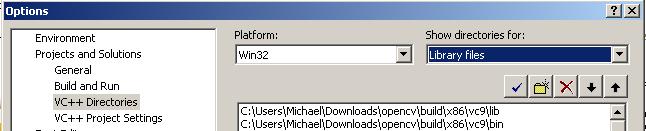
 Go to “Library files and add: “C:Program FilesZBarlib”
Go to “Library files and add: “C:Program FilesZBarlib”

3. Link libraries in current project
Create an empy blank console project
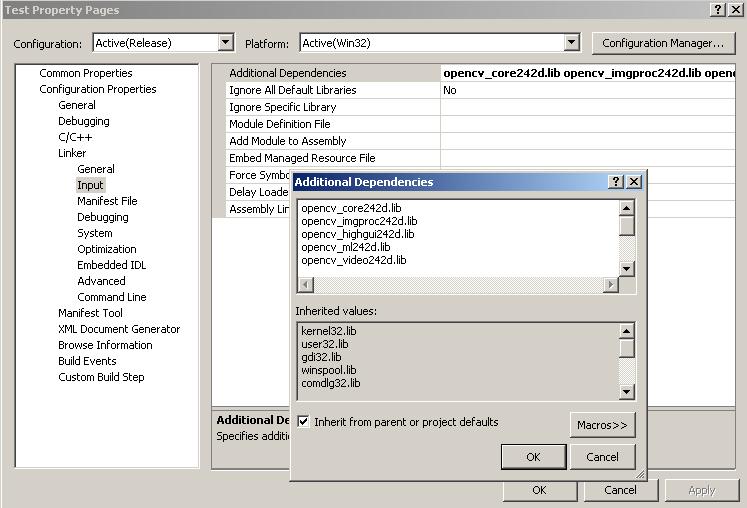
Right click your project -> Properties -> Configuration Properties -> Linker -> Input
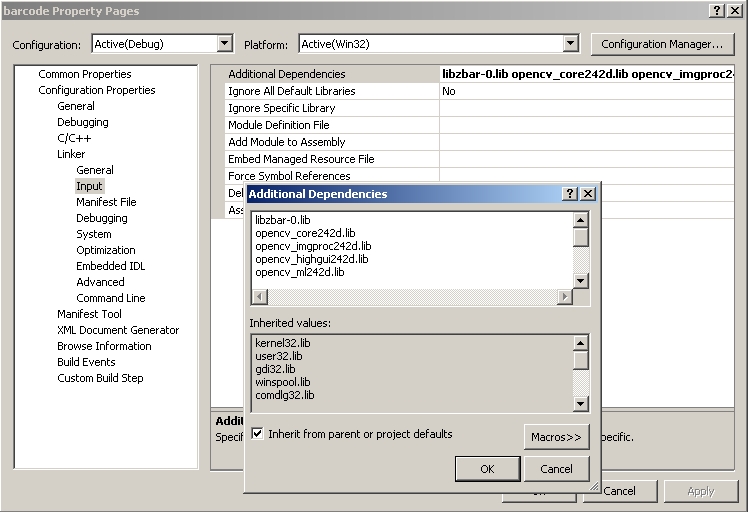

In additional dependencies copy and paste the following:
libzbar-0.lib
opencv_core242d.lib
opencv_imgproc242d.lib
opencv_highgui242d.lib
opencv_ml242d.lib
opencv_video242d.lib
opencv_features2d242d.lib
opencv_calib3d242d.lib
opencv_objdetect242d.lib
opencv_contrib242d.lib
opencv_legacy242d.lib
opencv_flann242d.lib
opencv_core242d.lib
opencv_imgproc242d.lib
opencv_highgui242d.lib
opencv_ml242d.lib
opencv_video242d.lib
opencv_features2d242d.lib
opencv_calib3d242d.lib
opencv_objdetect242d.lib
opencv_contrib242d.lib
opencv_legacy242d.lib
opencv_flann242d.lib
4. Test Program
Make a new file in your project: main.cpp
#include "zbar.h"
#include "cv.h"
#include "highgui.h"
#include <iostream>
using namespace std;
using namespace zbar;
using namespace cv;
int main(void){
ImageScanner scanner;
scanner.set_config(ZBAR_NONE, ZBAR_CFG_ENABLE, 1);
// obtain image data
char file[256];
cin>>file;
Mat img = imread(file,0);
Mat imgout;
cvtColor(img,imgout,CV_GRAY2RGB);
int width = img.cols;
int height = img.rows;
uchar *raw = (uchar *)img.data;
// wrap image data
Image image(width, height, "Y800", raw, width * height);
// scan the image for barcodes
int n = scanner.scan(image);
// extract results
for(Image::SymbolIterator symbol = image.symbol_begin();
symbol != image.symbol_end();
++symbol) {
vector<Point> vp;
// do something useful with results
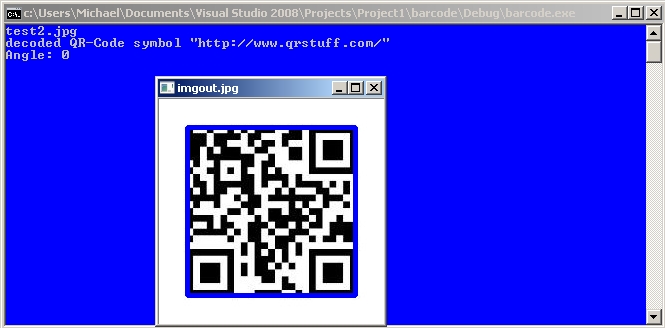
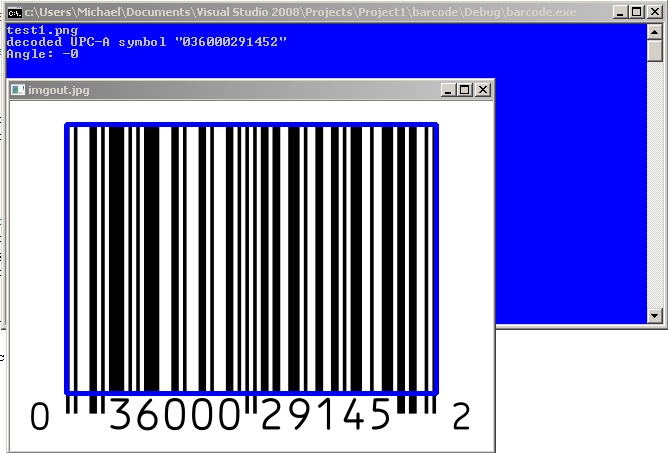
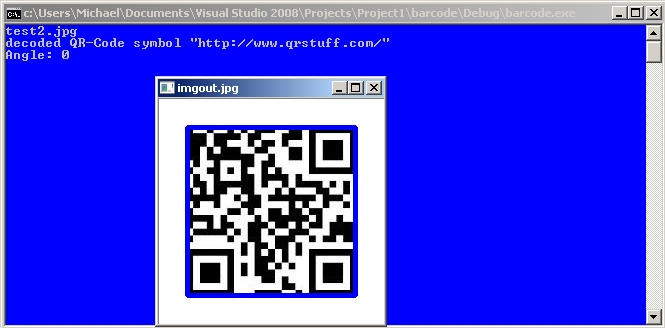
cout << "decoded " << symbol->get_type_name()
<< " symbol "" << symbol->get_data() << '"' <<" "<< endl;
int n = symbol->get_location_size();
for(int i=0;i<n;i++){
vp.push_back(Point(symbol->get_location_x(i),symbol->get_location_y(i)));
}
RotatedRect r = minAreaRect(vp);
Point2f pts[4];
r.points(pts);
for(int i=0;i<4;i++){
line(imgout,pts[i],pts[(i+1)%4],Scalar(255,0,0),3);
}
cout<<"Angle: "<<r.angle<<endl;
}
imshow("imgout.jpg",imgout);
// clean up
image.set_data(NULL, 0);
waitKey();
}
5. Copy libzbar-0.dll from C:/Program Files/ZBar/bin to your project folder
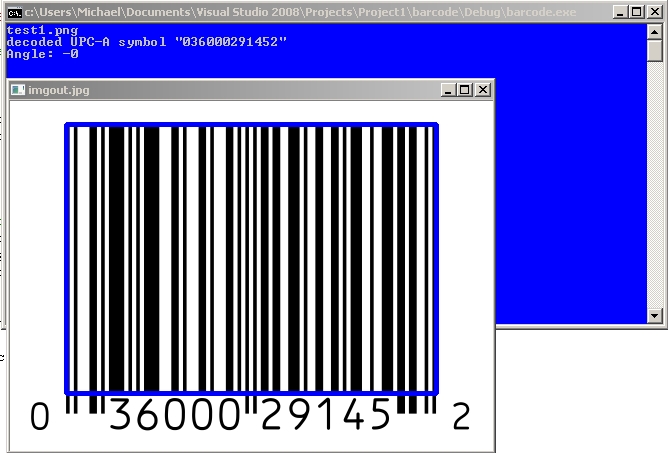
6. Run program


Sample Images