Tutorial: How to Install Tesseract OCR 3.02.02 for Visual Studios 2008 on Windows Vista
More updated tutorial: https://github.com/gulakov/tesseract-ocr-sample
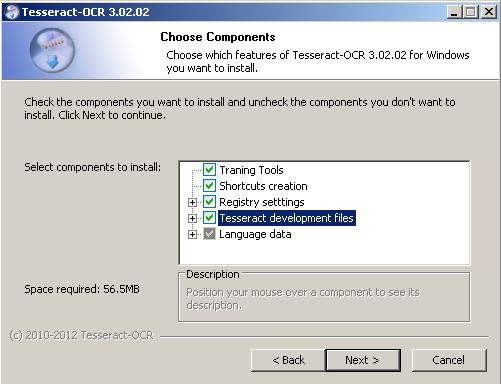
1. Download and install the full windows version of Tesseract. This way you won’t have to extract all the different separate files.
http://code.google.com/p/tesseract-ocr/downloads/detail?name=tesseract-ocr-setup-3.02.02.exe
Leave the destination folder as the default (C:Program FilesTesseract-OCR)
Remember to check Tesseract Development files!

2. Open up Microsoft Visual Studio 2008 and go to Tools -> Options
Project solutions -> VC++ Directories -> Show directories for include files


Add:
C:Program FilesTesseract-OCRinclude
C:Program FilesTesseract-OCRincludetesseract
C:Program FilesTesseract-OCRincludeleptonica
3. Next click show directories for -> Library Files
Add:
C:Program FilesTesseract-OCRlib

4. Configure linker options for Tesseract
Right click your project in solution explorer and click properties
Configuration Properties -> Linker->Input ->Additional Dependencies

Add this in there:
libtesseract302.lib
libtesseract302d.lib
liblept168.lib
liblept168d.lib
**You will have to do this for every project
***I think you can do this with the property sheets but I don’t know how to set it up. Message me if you do!
5. Copy liblept168.dll, liblept168d.dll, libtesseract302.dll and libtesseract302.dll from C:Program FilesTesseract-OCR into your project folder (Optional)
If for some reason when you run your program and you get .dll missing add these files into your project folder.
6. Hello World!
To check if your project works create your main cpp file with this code:
#include <baseapi.h>
#include <allheaders.h>
#include <iostream>
using namespace std;
int main(void){
tesseract::TessBaseAPI api;
api.Init(“”, “eng”, tesseract::OEM_DEFAULT);
api.SetPageSegMode(static_cast<tesseract::PageSegMode>(7));
api.SetOutputName(“out”);
cout<<“File name:”;
char image[256];
cin>>image;
PIX *pixs = pixRead(image);
STRING text_out;
api.ProcessPages(image, NULL, 0, &text_out);
cout<<text_out.string();
}
Copy this image into your project folder: (Right click save file as)

Copy eng.traineddata from C:Program FilesTesseract-OCRtessdata into your project folder and it should output Hello World! The traineddata file will be used as the data file for reading the text.

More to come! I will be making a tutorial maybe next week on linking OpenCV with Tesseract and maybe also on how to train Tesseract.