Determining Gender of a Name with 80% Accuracy Using Only Three Features
Introduction
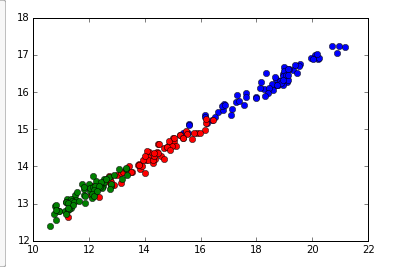
I thought an easy project to learn machine learning was to guess the gender of a name using characteristics of the name. After playing around with different features by encoding characters of the name, I discovered you only needed THREE features for 80% accuracy which is pretty impressive. I am by no means an expert at machine learning, so if you see any errors, feel free to point them out.
Example:
Name Actual Classified shea F F lucero F M damiyah F F nitya F F sloan M M porter F M jalaya F F aubry F F mamie F F jair M M
Dataset
Methodology
Loading
Code for loading data from dataset into numpy arrays ready for machine learning
import numpy as np from sklearn.cross_validation
import train_test_split, cross_val_score from sklearn.ensemble
import RandomForestClassifier from sklearn
import svm my_data = np.genfromtxt('names/yob2014.txt', delimiter=',', dtype=[('name','S50'), ('gender','S1'),('count','i4')], converters={0: lambda s:s.lower()})
my_data = np.array([row for row in my_data if row[2]>=20])
name_map = np.vectorize(name_count, otypes=[np.ndarray])
Xlist = name_map(my_data['name'])
X = np.array(Xlist.tolist())
y = my_data['gender']
X is an np.array of N * M, where N is number of names and M is number of features
y is M or F
name_map will be a function that converts a name (string) to an array of features
Fitting and Validation
for x in xrange(5): Xtr, Xte, ytr, yte = train_test_split(X, y, test_size=0.33) clf = RandomForestClassifier(n_estimators=100, min_samples_split=2) clf.fit(Xtr, ytr) print np.mean(clf.predict(Xte) == yte)
Picking Features
Character Frequency
def name_count(name):
arr = np.zeros(52)
for ind, x in enumerate(name):
arr[ord(x)-ord('a')] += 1
return arr
freq: [a:3, b:1, d:1]
0.690232056125
Character Frequency + Order
def name_count(name):
arr = np.zeros(52)
for ind, x in enumerate(name):
arr[ord(x)-ord('a')] += 1
arr[ord(x)-ord('a')+26] += ind+1
return arr
freq: [a:3, b:1, c:1]
ord: [a:6, b:4, c:5]
We can combine these encodings by adding the two arrays together and offsetting the second array
0.766864543983
0.760388559093
0.766864543983
0.76740420939
0.759848893686
Character Frequency + Order + 2-grams
def name_count(name):
arr = np.zeros(52+26*26)
# Iterate each character
for ind, x in enumerate(name):
arr[ord(x)-ord('a')] += 1
arr[ord(x)-ord('a')+26] += ind+1
# Iterate every 2 characters
for x in xrange(len(name)-1):
ind = (ord(name[x])-ord('a'))*26 + (ord(name[x+1])-ord('a'))
arr[ind] += 1
return arr
ord: [a:6, b:4, c:5]
2-gram: [ aa: 2, ab: 1, bc: 1]
Accuracy:
0.78548300054 0.771451699946 0.783864004317 0.777388019428 0.77172153265
We get a slight increase in accuracy, but I think we can do better.
Character Frequency + Order + 2-grams + Heuristics
def name_count(name):
arr = np.zeros(52+26*26+3)
# Iterate each character
for ind, x in enumerate(name):
arr[ord(x)-ord('a')] += 1
arr[ord(x)-ord('a')+26] += ind+1
# Iterate every 2 characters
for x in xrange(len(name)-1):
ind = (ord(name[x])-ord('a'))*26 + (ord(name[x+1])-ord('a')) + 52
arr[ind] += 1
# Last character
arr[-3] = ord(name[-1])-ord('a')
# Second Last character
arr[-2] = ord(name[-2])-ord('a')
# Length of name
arr[-1] = len(name)
return arr
ord: [a:6, b:4, c:5]
2-gram: [ aa: 2, ab: 1, bc: 1]
last_char: 3
second_last_char: 2
length: 5
0.801672962763 0.804641122504 0.803022126282 0.801672962763 0.805450620615
Fine-tuning
0.814085267134
0.821370750135
0.818402590394
0.825148407987
0.82245008095
Feature Reduction
[728 26 729 0 40 50 30 390 39 37] [728 26 729 50 0 40 37 30 34 390] [728 26 729 50 40 0 37 30 39 390] [728 26 729 0 50 40 30 37 390 39] [728 26 729 0 50 40 30 37 39 34]
These numbers refer to the feature index by most importance.
40 – order of o
def name_count(name):
arr = np.zeros(1)
arr[0] = ord(name[-1])-ord('a')+1
return arr
Accuracy:
0.771451699946 0.7536427415 0.753912574204 0.7536427415 0.760658391797
Wow! We actually get 75% accuracy! This means the last letter of a name is really important in determining the gender.
Let’s take the top three features (last and second last character and order of a’s) and see the importance of these. (But if you already read the title of this blog post, you should know what to expect.)
def name_count(name):
arr = np.zeros(3)
arr[0] = ord(name[-1])-ord('a')+1
arr[1] = ord(name[-2])-ord('a')+1
# Order of a's
for ind, x in enumerate(name):
if x == 'a':
arr[2] += ind+1
return arr
Accuracy:
0.798165137615 0.794117647059 0.795736643281 0.801133297356 0.803561791689
I would say 80% accuracy for 3 features is pretty good for determining gender of a name. Thats about the same accuracy as a mammogram detecting cancer in a 45-49 year old woman!
Sample Example
def name_count(name):
arr = np.zeros(3)
arr[0] = ord(name[-1])-ord('a')+1
arr[1] = ord(name[-2])-ord('a')+1
# Order of a's
for ind, x in enumerate(name):
if x == 'a':
arr[2] += ind+1
return arr
my_data = np.genfromtxt('names/yob2014.txt',
delimiter=',',
dtype=[('name','S50'), ('gender','S1'),('count','i4')],
converters={0: lambda s:s.lower()})
my_data = np.array([row for row in my_data if row[2]>=20])
name_map = np.vectorize(name_count, otypes=[np.ndarray])
Xname = my_data['name']
Xlist = name_map(Xname)
X = np.array(Xlist.tolist())
y = my_data['gender']
Xtr, Xte, ytr, yte = train_test_split(X, y, test_size=0.33)
clf = RandomForestClassifier(n_estimators=150, min_samples_split=20)
clf.fit(Xtr, ytr)
idx = np.random.choice(np.arange(len(Xlist)), 10, replace=False)
xs = Xname[idx]
ys = y[idx]
pred = clf.predict(X[idx])
for a,b, p in zip(xs,ys, pred):
print a,b, p
Output:
Name Actual Classified shea F F lucero F M damiyah F F nitya F F sloan M M porter F M jalaya F F aubry F F mamie F F jair M M
Conclusion
I hope you have learned something from reading this blog post as I did writing it!(Click here for Source: IPython Notebook)