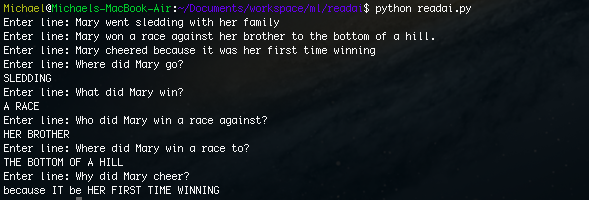
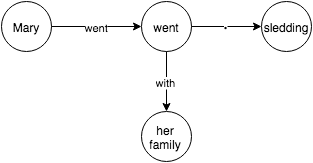
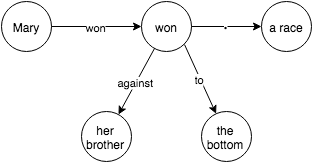
I was interested in an artificial intelligence that could do reading comprehension, but surprisingly, I could not find much on the topic. I decided to try and create an AI that could do some basic reading comprehension and I got some good results:
Short Passage (Input):
Mary went sledding with her family. Mary won a race against her brother to the bottom of a hill. Mary cheered because it was her first time winning.
Input: Where did Mary go?
Output: Sledding
Input: What did Mary win?
Output: A race
Input: Who did Mary win a race against?
Output: Her brother
Input: Where did Mary win a race to?
Output: The bottom of the hill
Input: Why did Mary cheer?
Output: Because it was her first time winning
As we can see, the program can actually answer the questions about the passage.
Full Source Available Here
Introduction
What I am trying to accomplish is program capable of artificial
semantic memory. Semantic memory refers to how we store our explicit knowledge and facts about the world. For example, our memory of our birth date or our knowledge that humans are mammals. I wanted to be able to make something that was able to read a passage and answer any questions I had.
Abstract Idea
An abstract idea of how I accomplished artificial semantic memory was to create a structure that can store a sentence in a different way that can be used to answer questions.
1. Structure the relationships betweens objects (nouns) in the sentence.
For example, in the sentence “Mary went sledding with her family”, there are three objects “Mary”, “sledding” and “her family”. Mary has a verb “go” (present tense of went) with the object “sledding”. The verb “go” is “with” the object “her parents”.
After brainstorming different ways to represent the relationships between objects and actions, I came up with a structure similar to a trie which I will call a “word graph”. In a word graph, each word is a node and the edges are actions or propositions.
Examples:
Mary went sledding with her family
Mary won a race against her brother to the bottom of the hill
Mary cheered because it was her first time winning
2. Answer questions using the structure.
A key observation to answering questions is that they can be reworded to be fill in the blanks.
Examples:
Where did Mary go -> Mary went _______
What did Mary win -> Mary won _______
Who did Mary win a race against? -> Mary won a race against _______
Why did Mary cheer -> Mary cheered because/since _______
We can use this observation to read out answers from our tree structure. We can parse the question, convert it to a fill in the blank format and then
Example:
Mary went _____
By following the tree, we see that we should put “sledding” in the blank.
Mary won _______
Mary won a race against ______
Mary won a race to ______
By following the tree, we see that Mary won “a race”, against “her brother”, to “the bottom”.
Implementation
I chose to implement this in Python since it is easy to use and has libraries to support natural language processing. There are three steps in my program: parsing, describing and answering.
Parsing converting a sentence to a structure that makes sense of the sentence structure.
Describing is reading in a sentence and adding the information to our tree structure.
Answering is reading in a question, changing the format and completing from our tree structure.
Parsing
The first thing we have to do is parse the sentence to see the sentence structure and to determine which parts of a sentence are objects, verbs and propositions. To do this, I used the
Stanford parser which works well enough for most cases.
Example: the sentence “Mary went sledding with her family” becomes:
(S
(NP (NNP Mary))
(VP
(VBD went)
(NP (NN sledding))
(PP (IN with) (NP (PRP$ her) (NN family)))))
The top level tree S (declarative clause) has two children, NP (noun phrase) and VP (verb phrase). The NP consist of one child NNP (proper noun singular) which is “Mary”. The VP has three children: VBD (verb past tense) which is “went”, NP, and a PP (propositional phrase). We can use the recursive structure of a parse tree to help us build our word graph.
A full reference for the parsers tags can be found here.
I put the Stanford parser files in my working directory but you might want to change the location to where you put the files.
os.environ['STANFORD_PARSER'] = '.'
os.environ['STANFORD_MODELS'] = '.'
parser = stanford.StanfordParser()
line = 'Mary went sledding with her family'
tree = list(parser.raw_parse(line))[0]
Describing
We can use the parse tree to build the word graph by doing it recursively. For each grammar rule, we need to describe how to build the word graph.
Our method looks like this:
# Returns edge, node
def describe(parse_tree):
...
if matches(parse_tree,'( S ( NP ) ( VP ) )'):
np = parse_tree[0] # subject
vp = parse_tree[1] # action
_, subject = describe(np) # describe noun
action, action_node = describe(vp) # recursively describe action
subject.set(action, action_node) # create new edge labeled action to the action_node
return action, action_node
....
We do this for each grammar rule to recursively build the word graph. When we see a NP (noun phrase) we treat it as an object and extract the words from it. When we see a proposition or verb, we attach it to the current node and when we see another object, we use a dot ( . ) edge to indicate the object of the current node.
Currently, my program supports the following rules:
( S ( NP ) ( VP ) )
( S ( VP ) )
( NP )
( PP ( . ) ( NP ) )
( PRT )
( VP ( VBD ) ( VP ) $ )
( VP ( VB/VBD ) $ )
( VP ( VB/VBZ/VBP/VPZ/VBD/VBG/VBN ) ( PP ) )
( VP ( VB/VBZ/VBP/VPZ/VBD/VBG/VBN ) ( PRT ) ( NP ) )
( VP ( VB/VBZ/VBP/VPZ/VBD/VBG/VBN ) ( NP ) )
( VP ( VB/VBZ/VBP/VPZ/VBD/VBG/VBN ) ( NP ) ( PP ) )
( VP ( VB/VBZ/VBP/VPZ/VBD/VBG ) ( S ) )
( VP ( TO ) ( VP ) )
( VP ( VB/VBZ/VBP/VPZ/VBD/VBG/VBN ) ( ADJP ) )
( VP ( VB/VBZ/VBP/VPZ/VBD/VBG/VBN ) ( SBAR ) )
( SBAR ( IN ) ( S ) )
For verbs, I used Nodebox (a linguistic library) for getting the present tense of a word so that the program knows different tenses of a word. E.g. “go” is the same word as “went”.
Answering
We can answer questions by converting the question to a “fill in the blank” and then following the words in the “fill in the blank” in the word graph to the answer. My program supports two types of fill in the blanks: from the end and from the beginning.
Type I: From the end
A from the end type of fill in the blank is a question like:
Where did Mary go?
Which converts to:
Mary went _______
And as you can see, the blank comes at the end of the sentence. We can fill in this blank by following each word in our structure to the answer. A sample of the code is below:
# Matches "Where did Mary go"
if matches(parse_tree, '( SBARQ ( WHADVP ) ( SQ ( VBD ) ( NP ) ( VP ) )'):
tokens = get_tokens(parse_tree) # Get tokens from parse tree
subject = get_node(tokens[3]) # Get subject of sentence
tokens = tokens[3:] # Skip first two tokens to make fill in the blank
return subject.complete(tokens) # Complete rest of tokens
The node completes by reading each token and following the corresponding edges. When we run out of tokens, we follow the first edge until we reach another object and return the edges followed and the object.
Simplified node.complete:
class Node:
...
def complete(self, tokens, qtype):
if len(tokens) == 0:
# no tokens left
if qtype == 'why':
# special case
return self.why()
if self.isObject:
# return object
return self.label
else:
# follow first until object
return self.first.label + self.first.complete(tokens, qtype)
else:
for edge, node in self:
if edge == tokens[0]:
# match rest of tokens
return node.complete(tokens, qtype)
return "No answer"
...
We have to handle “Why” as a special case because we need to complete with “because” or “since” after there are no more tokens and we have to iterate backwards to the first object.
Type 2: From the beginning
A from the beginning type is a question like:
Who went sledding?
Which converts to:
____ went sledding?
As we can see, the blank is at the beginning of the sentence and my solution for this was to iterate through all possible objects and see which objects have tokens that match the rest of the fill in the bank.
Further Steps
There is still a long way to go, to make an AI perform reading comprehension at a human level. Below are some possible improvements and things to handle to make the program better:
Grouped Objects
We need to be able to handle groups of objects, e.g. “Sarah and Sam walked to the beach” should be split into two individual sentences.
Pronoun Resolution
Currently, pronouns such as he and she are not supported and resolution can be added by looking at the last object. However, resolution is not possible in all cases when there are ambiguities such as “Sam kicked Paul because he was stupid”. In this sentence “he” could refer to Sam or Paul.
Synonyms
If we have the sentence: “Jack leaped over the fence”, the program will not be able to answer “What did Jack jump over” since the program interprets jump as a different word than leap. However, we can solve this problem by using asking the same question for all synonyms of the verb and seeing if any answers work.
Augmented Information
If we have the sentence “Jack threw the football to Sam”, the program would not be able to answer “Who caught the football”. We can add information such as “Sam caught the football from Jack” which we can infer from the original sentence.
Aliasing
Sometimes objects can have different names, e.g. “James’s dog is called Spot” and the program should be able to know that James’ dog and Spot both refer to the same object. We can do this by adding a special rule for words such as “called”, “named”, “also known as” , etc.
Other
There are probably other quirks of language that need to be handled and perhaps instead of explicitly handling all these cases, we should come up with a machine learning model that can read many passages and be able to construct a structure of the content as well as to augment any additional information.
Full Source Available Here