A Simple Artificial Intelligence Capable of Basic Reading Comprehension
Short Passage (Input):
Mary went sledding with her family. Mary won a race against her brother to the bottom of a hill. Mary cheered because it was her first time winning.
Input: Where did Mary go?
Output: Sledding
Input: What did Mary win?
Output: A race
Input: Who did Mary win a race against?
Output: Her brother
Input: Where did Mary win a race to?
Output: The bottom of the hill
Input: Why did Mary cheer?
Output: Because it was her first time winning
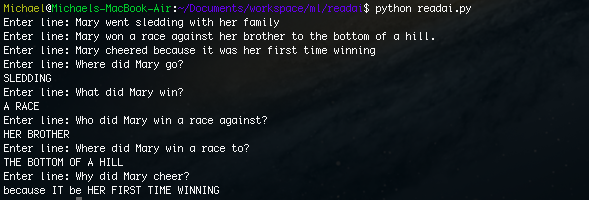
As we can see, the program can actually answer the questions about the passage.
Introduction
Abstract Idea
1. Structure the relationships betweens objects (nouns) in the sentence.
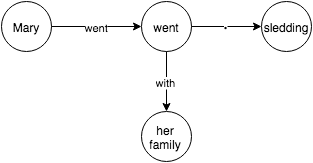
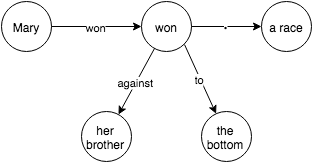

2. Answer questions using the structure.
Implementation
Parsing
A full reference for the parsers tags can be found here.
os.environ['STANFORD_PARSER'] = '.' os.environ['STANFORD_MODELS'] = '.' parser = stanford.StanfordParser() line = 'Mary went sledding with her family' tree = list(parser.raw_parse(line))[0]
Describing
Our method looks like this:
# Returns edge, node
def describe(parse_tree):
...
if matches(parse_tree,'( S ( NP ) ( VP ) )'):
np = parse_tree[0] # subject
vp = parse_tree[1] # action
_, subject = describe(np) # describe noun
action, action_node = describe(vp) # recursively describe action
subject.set(action, action_node) # create new edge labeled action to the action_node
return action, action_node
....
Currently, my program supports the following rules:
( S ( NP ) ( VP ) )
( S ( VP ) )
( NP )
( PP ( . ) ( NP ) )
( PRT )
( VP ( VBD ) ( VP ) $ )
( VP ( VB/VBD ) $ )
( VP ( VB/VBZ/VBP/VPZ/VBD/VBG/VBN ) ( PP ) )
( VP ( VB/VBZ/VBP/VPZ/VBD/VBG/VBN ) ( PRT ) ( NP ) )
( VP ( VB/VBZ/VBP/VPZ/VBD/VBG/VBN ) ( NP ) )
( VP ( VB/VBZ/VBP/VPZ/VBD/VBG/VBN ) ( NP ) ( PP ) )
( VP ( VB/VBZ/VBP/VPZ/VBD/VBG ) ( S ) )
( VP ( TO ) ( VP ) )
( VP ( VB/VBZ/VBP/VPZ/VBD/VBG/VBN ) ( ADJP ) )
( VP ( VB/VBZ/VBP/VPZ/VBD/VBG/VBN ) ( SBAR ) )
( SBAR ( IN ) ( S ) )
For verbs, I used Nodebox (a linguistic library) for getting the present tense of a word so that the program knows different tenses of a word. E.g. “go” is the same word as “went”.
Answering
Type I: From the end
A from the end type of fill in the blank is a question like:
Where did Mary go?
Which converts to:
Mary went _______
And as you can see, the blank comes at the end of the sentence. We can fill in this blank by following each word in our structure to the answer. A sample of the code is below:
# Matches "Where did Mary go" if matches(parse_tree, '( SBARQ ( WHADVP ) ( SQ ( VBD ) ( NP ) ( VP ) )'): tokens = get_tokens(parse_tree) # Get tokens from parse tree subject = get_node(tokens[3]) # Get subject of sentence tokens = tokens[3:] # Skip first two tokens to make fill in the blank return subject.complete(tokens) # Complete rest of tokens
Simplified node.complete:
class Node:
...
def complete(self, tokens, qtype):
if len(tokens) == 0:
# no tokens left
if qtype == 'why':
# special case
return self.why()
if self.isObject:
# return object
return self.label
else:
# follow first until object
return self.first.label + self.first.complete(tokens, qtype)
else:
for edge, node in self:
if edge == tokens[0]:
# match rest of tokens
return node.complete(tokens, qtype)
return "No answer"
...
Type 2: From the beginning
A from the beginning type is a question like:
Who went sledding?
Which converts to:
____ went sledding?
As we can see, the blank is at the beginning of the sentence and my solution for this was to iterate through all possible objects and see which objects have tokens that match the rest of the fill in the bank.
Further Steps
Grouped Objects
We need to be able to handle groups of objects, e.g. “Sarah and Sam walked to the beach” should be split into two individual sentences.
Pronoun Resolution
Synonyms
If we have the sentence: “Jack leaped over the fence”, the program will not be able to answer “What did Jack jump over” since the program interprets jump as a different word than leap. However, we can solve this problem by using asking the same question for all synonyms of the verb and seeing if any answers work.
Augmented Information
If we have the sentence “Jack threw the football to Sam”, the program would not be able to answer “Who caught the football”. We can add information such as “Sam caught the football from Jack” which we can infer from the original sentence.
Aliasing
Sometimes objects can have different names, e.g. “James’s dog is called Spot” and the program should be able to know that James’ dog and Spot both refer to the same object. We can do this by adding a special rule for words such as “called”, “named”, “also known as” , etc.
Other
There are probably other quirks of language that need to be handled and perhaps instead of explicitly handling all these cases, we should come up with a machine learning model that can read many passages and be able to construct a structure of the content as well as to augment any additional information.
Leave a Reply to Unknown Cancel reply